这篇文章主要是介绍Fisher Information,也称费雪信息。
basics
fisher information,记为IX(θ), 产生的随机变量X的参数θ的费雪信息。其数学表示式写为期望:
IX(θ)=EX((dθdlogf(x∣θ))2)=∫X(dθdlogf(x∣θ))2pθ(x)dx)
上式中微分表达 dθdlogf(x∣θ)被称之为score function, 用来描述参数变化时模型的敏感度(f函数值变化程度)。
从这个数学表达上看fisher information在局部最优时可以看作score function的二阶矩. 此外因为在局部最优点,其期望为0则可以推断fisher information时score function的方差。
IX(θ)=EX(S(x,θ)2)−0=EX(S(x,θ)2)−EX(S(x,θ))2=VAR(S(x,θ))
因此费雪信息可以用来估计MLE估计结果处score function, 也就是log likelihood梯度的方差
如果对n个iid的X抽样做建模,IXn(θ)=nIX(θ), 因此IX(θ)被称之为单位费雪信息. 这个等式表明,对于同一个分布,采样次数越多,对参数估计准确率越高,信息也就越多。
此外,费雪信息在密度函数满足一定的平滑条件时,可以写为:
IX(θ)=−EX(dθ2d2logf(x∣θ))=−∫Xdθ2d2logf(x∣θ)pθ(x)dx
二阶导在几何角度看描述了函数的弯曲程度,也就是函数在该点凸(二阶导大于等于0)和凹(二阶导小于等于0)的程度。这里也就是描述了log likelihood在局部最优的情况,越大说明在局部最优的弯曲程度大,置信区间越窄,数据越可信。
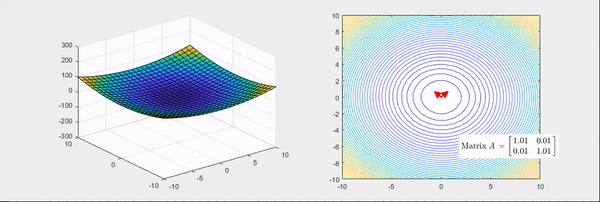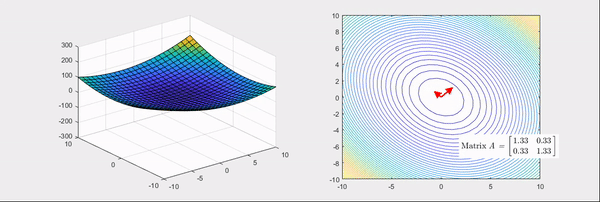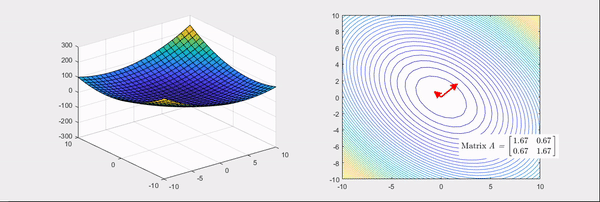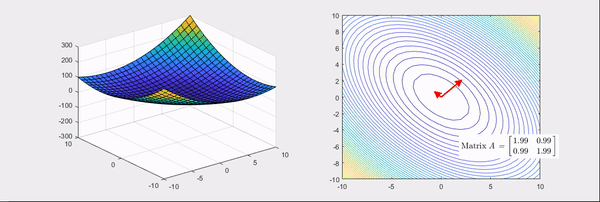
从这个角度再看上面的定义,所谓log likelihood梯度的方差,只有再弯曲程度越大的地方周围区域梯度会剧烈变化,方差很大。这个角度看,两个定义本质一致,平滑条件是为了满足任意阶可导。
在针对高维数据计算费雪信息时,其结构呈矩阵称之为Fisher Information Matrix. 这种情况下,矩阵可以写为:
IX(θ)=EX(∇logf(X∣θ)∇logf(X∣θ)T)=−EX(Hlogf(X∣θ))
与参数估计的联系:Cramér–Rao lower bound
对于通过MSE做无偏估计获得的参数,受Cramér–Rao lower bound定理约束,满足以下大小关系:
VAR(T)≥∇ϕ(θ)TIθ−1∇ϕ(θ)
表达式中ϕ(θ)表示生成数据的统计量函数,而T表示对该函数的无偏估计。
这样当我们带入函数ϕ(θ)=λθ时,∇ϕ(θ)=λ, 相应表达式变成VAR(λT)≥λTIθ−1λ, 这样最终获得针对无偏估计得到参数的不等式:
Cov(T)≥Iθ−1
此外,参考Detian Deng大神的回答,MLE估计到的参数渐进分布的方差是Iθ−1。记为:
n(θMLE−θ)→N(0,Iθ−1)
与KL散度的联系:二阶近似
在一定的平滑条件下,可以建立KL散度与Fisher Information之间的关系:
KL(Pθ1∣∣∣∣Pθ2)≃21(θ1−θ2)TIX(θ1)(θ1−θ2)
定义自然梯度
借助这一性质,在信息几何中定义出自然梯度,相对于欧氏空间中的梯度计算:
ϵ→0lim∣∣d∣∣≤ϵargminL(θ+d)
上式可以解释为:向参数空间上某d向量方向走出欧氏空间测量的一小步,使Loss function 更小,选取其中效果最好的d更新参数
信息几何在概率空间使用KL散度作为距离调整了参数更新的目标:
ϵ→0limKL(θ∣∣∣∣θ+d)≤ϵargminL(θ+d)
也就是向参数空间上某d向量方向走出概率空间测量的一小步,使Loss function 更小,选取其中效果最好的d更新参数
写为拉格朗日乘子为:
minL(θ+d)+λ(KL(θ∣∣∣∣θ+d)−ϵ)≃L(θ)+∇L(θ)Td+λ(21dTIX(θ)d−ϵ)
对右边针对变量d做梯度,并使梯度为0,则获得∇L(θ)+λIX(θ)d=0
从而推得d=−λ1IX−1(θ)∇L(θ)
这样我们获得自然梯度的常用定义:
∇h=IX−1∇h
References
Photo by National Cancer Institute on Unsplash
